回应模式 - No.63341265
No.63341265 - 技术宅
无标题无名氏No.63341265 只看PO
2024-08-05(一)11:31:04 ID:6gbuo8q 回应
求助肥哥们,如何从头写一个偏独立的ai?( ;´д`)
先叠个甲,po不是计算机专业的学生所以一些表述可能不太准确还请见谅。
想要达到的效果类似于一个独立的聊天机器人,可以通过训练让聊天至少有逻辑一些,最好能通过对话简单判断人类的情绪。
如果要从头开始,需要下载什么软件?有什么样的硬件基础?并学习什么编程语言?
无标题无名氏No.63365803
2024-08-07(三)04:28:47 ID: YfgpobQ
>>No.63365499
>有没有需求:
太有了。不只是商业应用,如果能解决面对长序列的权重衰退问题,那你的文章可能就是下一篇attention is all your need
>从哪开始:
不妨先从最基础的rnn开始,看看问题最初的样子;然后沿着网络结构发展史一路看过来,了解目前大家为解决这个问题做了哪些成功的尝试
另:
我个人感觉吴恩达的课即使在七八年前也称不上很好,在现在想通过这门课来入门并不是很好的选择
我的建议是初期多看带各种可视化的博客/笔记,获取宏观认知。深入靠实践,动手写写比看别人干推公式更有用
无标题无名氏No.63365905
2024-08-07(三)06:11:44 ID: LAmxdWY
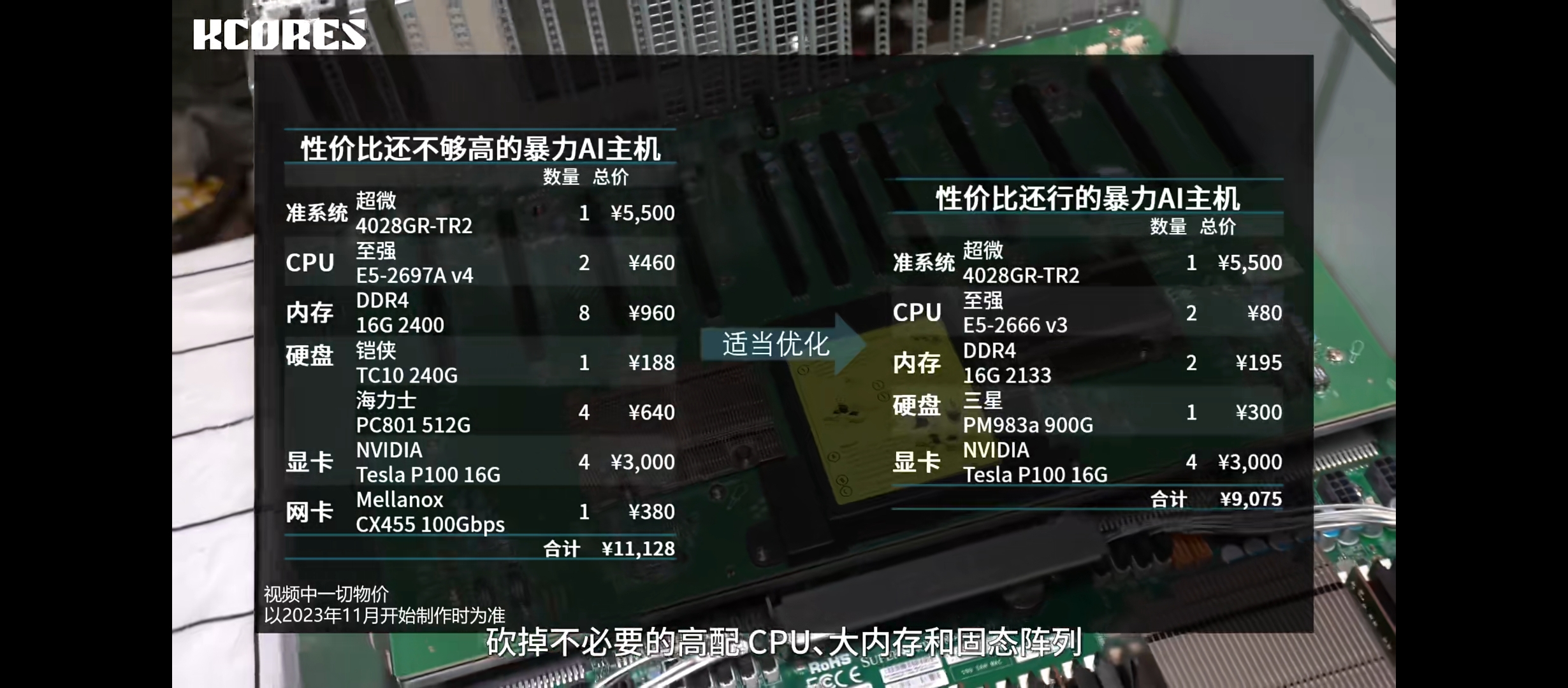
之前看的一个视频,他用左边这套配置跑起了70b的模型,但是视频只是演示不是教程,实际自己操作可能要学很多很多东西,po最好仔细考虑一下再决定是否入手
无标题无名氏No.63365932
2024-08-07(三)06:34:05 ID: LAmxdWY

我也是纯小白,我现在想实现的是“以最低成本没有限制的和ai涩涩”现在我找到的办法只有酒馆+克劳德,但是发现他们封杀曲奇的速度实在是快所以就没动力折腾了,不知道肥哥们有没有办法实现我这个愿望( ´д`)人
jp
无标题无名氏No.63367290
2024-08-07(三)10:37:21 ID: 6gbuo8q (PO主)
我知道凭兴趣坚持下去很难,并且物质条件和我的个人能力目前都不支持我的想法,但是我确实不是一时兴起才打算做这个的,想了挺久的。
目前电脑硬件这一块我已经在想办法了,我想的是能不能先从个人能力这块先去做一些改变,哪怕最后失败了能学到一些东西也是好的(つд⊂)
无标题无名氏No.63367313
2024-08-07(三)10:39:39 ID: 6gbuo8q (PO主)
肥哥们如果有比较懂的,可以把大致需要了解的东西,掌握的技能列一下告诉我,我会尽力去了解去学,也会自己找一些参考和视频,po在这里先谢谢大家了
无标题无名氏No.63386982
2024-08-08(四)20:57:04 ID: g82xgaF
>>No.63360851
coze.com支持部署到discord bot等等的app端。
至于收费什么的,emm确实是个问题。应该是频率和每天的次数限制,但可以通过整好几个一模一样的bot暂时解决|∀゚
无标题无名氏No.63406238
2024-08-10(六)13:09:17 ID: 83YvGLK
>>No.63365803
谢谢建议,这几天搜索了一下相关的内容,对主要的问题和大致的解决方法有了一些了解,但我不是很确定,这个问题是否是只需要改进架构如MoE架构或transformer架构就能解决,还是必须要想出新的架构?
以及我察觉到,我对长期记忆感兴趣的初衷是想尽量避免和有设定的AI聊天时ooc的现象,我问了chatgpt4o ooc的原因和解决方法,得到的答案是,除了prompt的细化以及聊天时使用一些技巧,还可以进行分段记忆管理、进行语境模型训练、改进Transformer架构、优化模型、改进目标函数等,扩展上下文窗口大小只是方法之一,如果改进长期记忆不能显著解决ooc的问题,我就不是很有动力继续钻研下去了,但是现在我完全看不出来,改进长期记忆是否能显著改善ooc的问题?
以及能问下不推荐吴恩达课程的原因吗?机器学习那门课很多年前我跟完了,感想是讲得很细、太细了,很多一时半会儿用不到的东西,不过原理讲得很清楚,到现在我还记得传播函数是怎么一回事以及课后项目推荐系统的大致原理,是因为它太细会分散精力所以不推荐吗?看了下后面的深度学习专项训练,发现自然语言处理这块放到了最后一门课程,前面几门课程还是对机器学习课程的扩展,从coursera给的那个目录来看的话感觉讲得挺细的
无标题无名氏No.63501845
2024-08-19(一)02:30:36 ID: YfgpobQ
>>No.63406238
>改进架构or提出新架构
这两种方法都是有可能的,但是对入门来说这些工作还是太超前了。
在成为这方面的专家之前,建议先跟着导师搞——毕竟如果能对SOTA做有效改进,也是很不错的工作了。
>能不能改善ooc
答案是能,但是这是非常困难的路线;类似lora的解决方案看起来更切实一些。
让llm智能到可以扮演好一个角色是那种非常正确,非常重要但是很遥远的目标
但如果用lora直接给它洗脑成对应的角色,那没有扮演自然就没有ooc了
>为什么不推荐吴恩达入门
一本说文解字很有价值;但一个刚开始学中文的人该看的是一些有趣的小故事,而不是说文解字
首先是效率问题。
让一个机器学习新手看这个,那可能有一半以上的时间是“知道他在算一个东西,可是不知道为什么要算这个”
然后在数年后某一天回看:“哦原来这里推的是这个,当时完全不知道,结果最后也没记住”
另一方面就是时效性问题。
且不说老框架老项目好不好复现的问题。业界的认知也是不断迭代的
新手期如果只靠旧认知入门,容易出现一些奇怪的盲区,多少有点给自己的未来埋雷的意思。
无标题无名氏No.63542936
2024-08-23(五)07:25:41 ID: Gs2SdhS
>>No.63367313
prompt engineering + rag,没必要用本地大模型,直接用在线服务,gpt之类的。在线大模型的性能和各方面素质要远强于本地量化的小模型。这样基本就没有本地硬件需求,只用给在线模型捐点使用费。
记忆问题(我理解你需要的是模型记住你想让他知道的知识而不是long context)不做pretraining只能靠rag解决,pretraining的价格不是正常人甚至正常实验室能付得起的。
finetuning性价比很低。