看看我的:
CREATE Table #tb(
Id integer,
day1 varchar(10),
day2 varchar(10),
day3 varchar(10),
day4 varchar(10)
);
DECLARE @Targ varchar(10);
SET @Targ = 'y';
INSERT INTO #tb VALUES( 1, 'n', 'y', 'y', 'y');
INSERT INTO #tb VALUES( 2, 'n', 'y', 'y', 'n');
INSERT INTO #tb VALUES( 3, 'n', 'n', 'y', 'n');
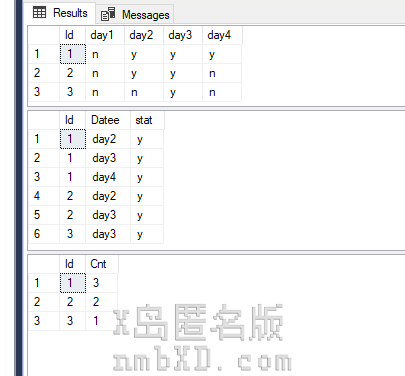
SELECT * FROM #tb;
WITH map AS(
SELECT
Id, Datee, stat
FROM
#tb
UNPIVOT(
stat FOR Datee IN (day1, day2, day3, day4) ) pv
WHERE pv.stat = @Targ
)
SELECT * FROM map;
DROP TABLE #tb;
效果如图(省略了一个GroupBy,自己写吧,WithAs不能调两遍太丑了).


{kind=link}